
On the Lost Nuance of Grep vs. Semantic Search
the answer is...it depends

Two years ago, RAG (Retrieval Augmented Generation) meant vector databases and embedding models. Now, Claude Code, Codex, Cline, and others have popularized a vector-less approach by using grep, bash tools, and good ‘ole reasoning. If you took Twitter, the everything App, as conventional wisdom, then you might believe that vectors are overkill and agentic search with grep1 is really all you need.
That is until Cursor published a blog on how they use vector search alongside grep. Who knew there could be nuance!
A Really Contrived Example
My initial reaction to agentic search was one of (naive) dismissal. What a waste of compute! Why use all of your hard earned Jenson Bucks when you have a compact, efficient embedding model that understands language? This vector-less approach clearly works. When does it not work? Is it always superior to vectors?
So I built a really dumb testbed. I split out each row from the Natural Questions corpus and saved it as a text file. For each query, I removed stop words and grep’d all documents that had a match to any of the remaining keywords2.
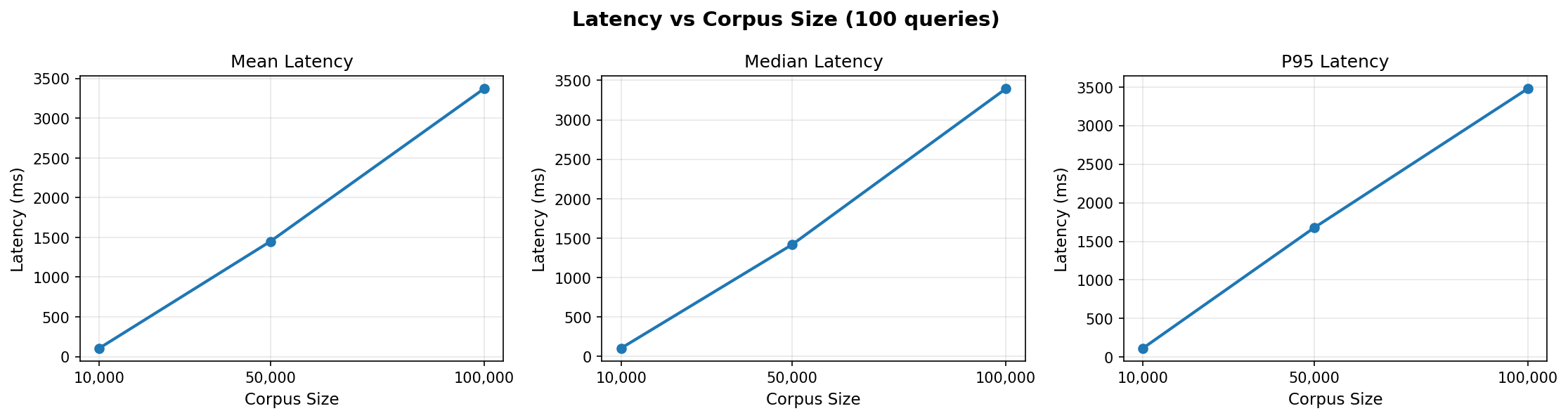
Simple! But slow3.
Latency seems to scale linearly with index size and is much slower than numpy on my Macbook.
Unsurprisingly, using only the keywords present in the query showed poor performance. We don’t get the soft matching and flexibility of embeddings. We only find matches to the correct document when there is an exact keyword match between the query and document.
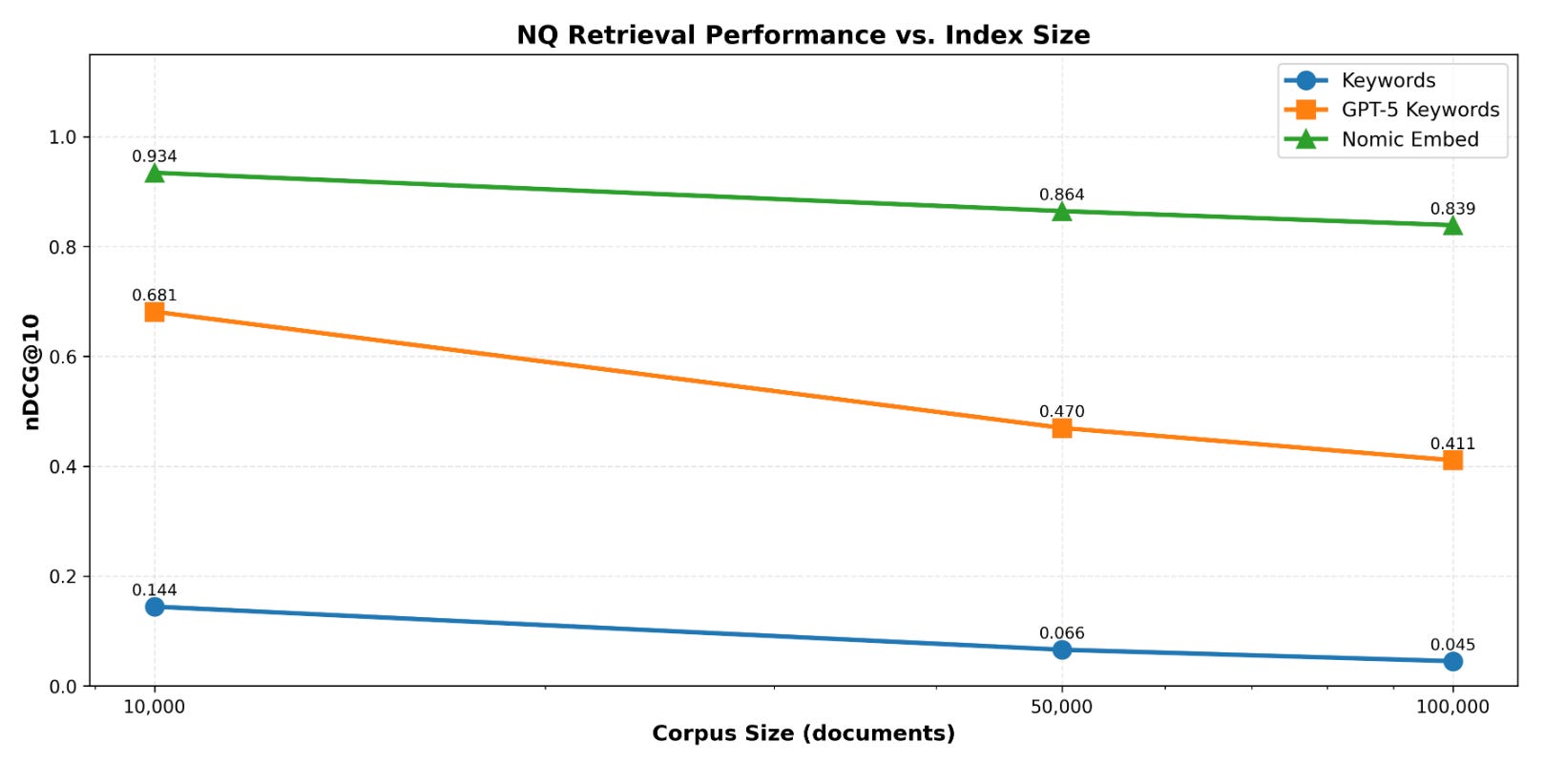
But using a cheap model like gpt-5-mini to return relevant keywords based on the query nearly 10x’d performance4
So what is grep good for? Exact matches for a known or easily derived keyword5. But that keyword may not always be known.
RAG is Dead…Long Live RAG?
Compared to a numpy vector search, grep is much slower. But embedding models converge to a bag of semantic tokens and don’t offer much flexibility for queries outside of its training data.
Take the BRIGHT benchmark: many models have shifted to include some sort of rewriting and expansion. ReasonIR showed that training with expanded queries6 and reranking with an LLM7 improved over their baseline.
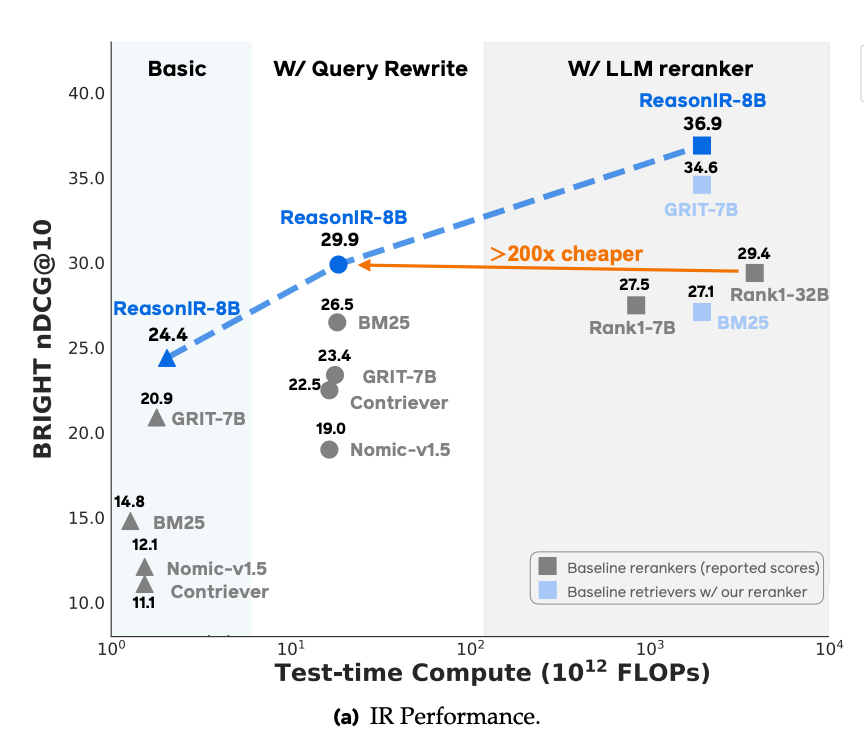
In a nutshell, you’re trading latency and tokens for flexibility when using grep+keywords over embeddings.
But when should you use either?
Seconds describes it quite clearly:
If it’s not readily apparent what the name of a variable or a particular stage of your pipeline is, but you can reference some oblique aspect of it, embeddings will get you a lot closer than grep will.
Cursor’s Embedding Model
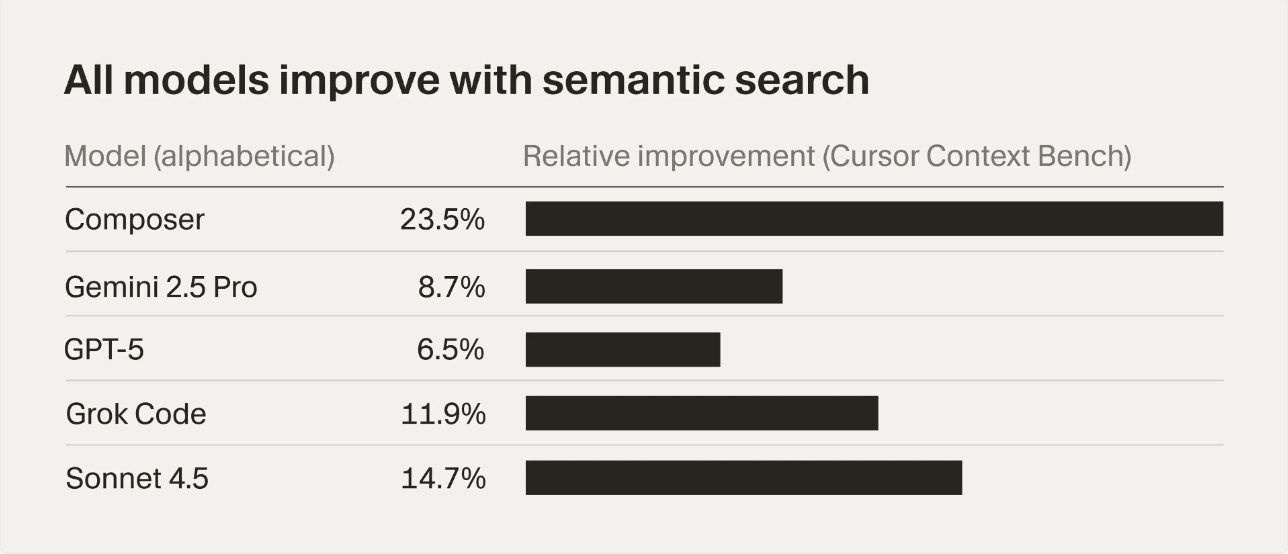
Cursor’s embedding model seems to improve performance for all models on their internal Cursor Context Bench.
So how is it different than a regular code embedding model? They leverage the rich user-agent interactions:
We provide these traces to an LLM, which ranks what content would have been most helpful at each step. We then train our embedding model to align its similarity scores with these LLM-generated rankings. This creates a feedback loop where the model can learn from how agents actually work through coding tasks, rather than relying on generic code similarity.
Taking the traces (expanded query), they train an embedding model to retrieve documents that were found from an agent using tools like grep and file read. This is quite similar to ReasonIR! While they may not be explicitly modeling query/keyword expansion, training over the traces distills that information from grep and file read.
Is it be better for the embedding model to explicitly learn to do the query expansion or learn it implicitly by mining the correct traces? Maybe SPLADE is another alternative. Who knows, but it would be fun to try :)
At the end of the day, comparisons of grep to semantic search are missing context. Agentic Search gives you flexible retrieval by offloading the learned semantics of an embedding model to an LLM. This also makes using grep in any codebase simple. You no longer have to maintain an index, worry about any potential security implications, or think about how to best chunk your files for your embedding model. However, I believe that Agentic Search shows where embedding models can and should improve.
“with grep” is doing a lot of heavy lifting here
Functionally, I did this f”rg -i -c {‘|’.join(query)}”. Docs are “scored” by counts of each word. Because this is a toy example, I didn’t bother with any score normalization. We could use BM25 if we wante d
Cognition recently trained specialized models for faster (and parallel) agentic retrieval.
It’s not lost on me that this dataset is really popular and probably not the most fair comparison. However
However, embeddings are still the way to go for the continuous domain
It’s worth noting that the model itself doesn’t rewrite the queries
This even works using an off-the-shelf LLM